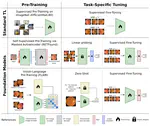
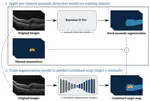
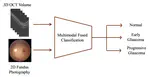
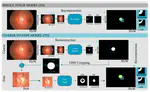
Junde Wu,
Huihui Fang,
Fei Li,
Huazhu Fu,
Fengbin Lin,
Jiongcheng Li,
Yue Huang,
Qinji Yu,
Sifan Song,
Xinxing Xu,
Yanyu Xu,
Wensai Wang,
Lingxiao Wang,
Shuai Lu,
Huiqi Li,
Shihua Huang,
Zhichao Lu,
Chubin Ou,
Xifei Wei,
Bingyuan Liu,
Riadh Kobbi,
Xiaoying Tang,
Li Lin,
Qiang Zhou,
Qiang Hu,
Hrvoje Bogunović,
José Ignacio Orlando,
Xiulan Zhang,
Yanwu Xu